Sie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr InformationenIn diesem Beitrag zeige ich dir, wie du in SharePoint die Felder Ersteller und Bearbeiter mit Power Automate anpasst. Wenn du mit Listen arbeitest, merkst du relativ schnell, dass die Standardfelder „Erstellt von“ und „Geändert von“ nicht immer zu deinen fachlichen Anforderungen passen. Gerade dann, wenn Prozesse automatisiert laufen oder Daten aus anderen Systemen kommen, stimmen diese Werte oft nicht mit der Realität überein. Dadurch entsteht ein Bruch zwischen technischer Umsetzung und fachlicher Sicht, und genau das kann später für Verwirrung sorgen.
Ein klassisches Beispiel ist die Integration externer Datenquellen. Wenn Informationen aus einem CRM oder Ticketsystem übernommen werden, dann erfolgt die Erstellung der Einträge meist automatisiert. Dadurch steht in den Feldern häufig ein technischer Benutzer oder ein Service-Account, obwohl die Daten ursprünglich von ganz anderen Personen stammen. Gleichzeitig passiert es oft, dass ein Flow Einträge im Namen anderer Benutzer erstellt, etwa um Prozesse zu vereinheitlichen oder Berechtigungen sauber zu halten. Auch hier geht die eigentliche Information verloren, wer den Inhalt wirklich angelegt oder geändert hat.
Zusätzlich wird es bei Migrationen interessant. Wenn du Daten aus Excel, einer alten Liste oder sogar aus einem komplett anderen System übernimmst, dann werden die Einträge in vielen Fällen neu erstellt. Das führt dazu, dass plötzlich alle Elemente denselben Ersteller haben, obwohl die Inhalte historisch von unterschiedlichen Personen stammen. Dadurch verlierst du wichtige Kontextinformationen, die für Nachvollziehbarkeit und Auditing entscheidend sein können.
Ein weiteres häufiges Szenario sind zentral verarbeitete Formulare. Nutzer geben Daten über ein Formular ein, im Hintergrund übernimmt jedoch ein zentraler Prozess die Verarbeitung und Speicherung. Technisch gesehen ist dann dieser Prozess der Ersteller, fachlich gesehen jedoch der Benutzer, der das Formular ausgefüllt hat. Genau diese Diskrepanz sorgt oft für Rückfragen oder Missverständnisse im Team.
Damit deine Daten nicht nur technisch korrekt, sondern auch fachlich sinnvoll sind, ist es wichtig zu verstehen, wie du die Felder „Erstellt von“ und „Geändert von“ gezielt beeinflussen kannst. In diesem Artikel zeige ich dir, welche Möglichkeiten du hast, wo die Grenzen liegen und wie du typische Szenarien sauber und nachvollziehbar umsetzt.
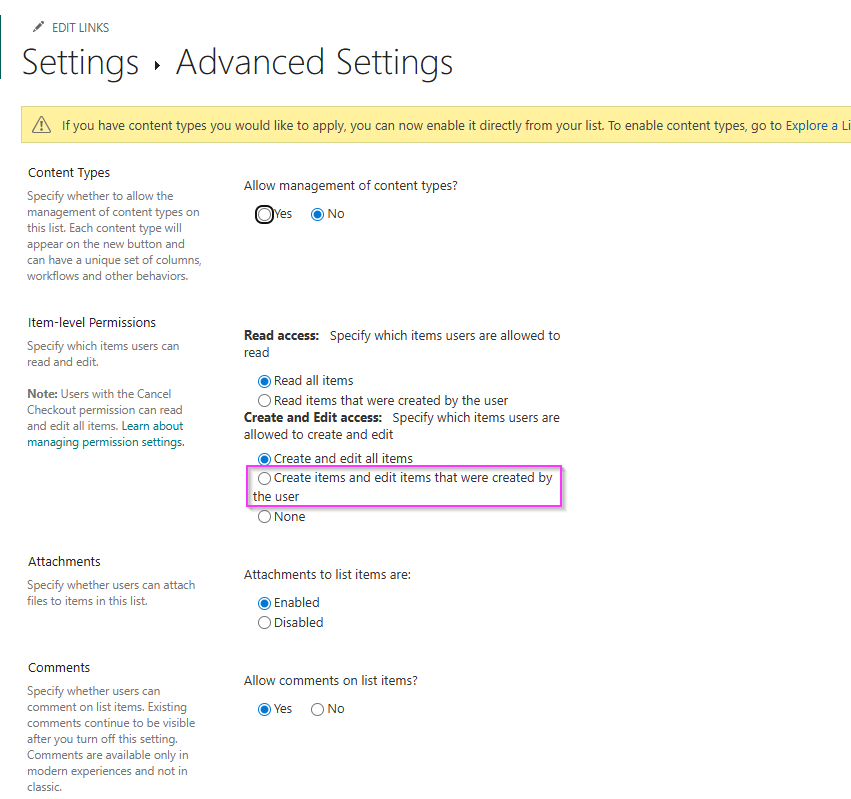
SharePoint Erweiterte Listeneinstellung
Wenn du mit Listen arbeitest, kommst du früher oder später an den Punkt, an dem du dich mit den erweiterten Berechtigungen beschäftigst. Eine der am häufigsten genutzten Einstellungen ist dabei die Einschränkung, dass Benutzer nur ihre eigenen Einträge bearbeiten dürfen. Auf den ersten Blick wirkt das sinnvoll, sauber und kontrolliert. Schließlich willst du verhindern, dass Nutzer wahllos Daten anderer verändern. In der Praxis zeigt sich aber schnell, dass genau diese Einstellung auch ihre Schattenseiten hat, besonders dann, wenn sich Strukturen ändern oder Benutzer das Unternehmen verlassen.
Und genau hier wird es interessant. Denn ohne eine durchdachte Lösung kann dir diese Konfiguration schneller Probleme verursachen, als dir lieb ist. Prozesse, die vorher stabil liefen, geraten ins Stocken, Verantwortlichkeiten sind nicht mehr klar zugeordnet und plötzlich stehst du vor der Herausforderung, bestehende Daten wieder bearbeitbar zu machen. Das Ganze ist kein Sonderfall, sondern ein absolut typisches Szenario in vielen Projekten.
Schauen wir uns kurz an, wo das Problem eigentlich entsteht. In den erweiterten Einstellungen deiner Liste gibt es unter den Item-level Permissions die Option, dass Benutzer nur die Elemente bearbeiten dürfen, die sie selbst erstellt haben. Technisch bedeutet das: Jeder sieht alle Einträge, aber bearbeiten kann sie nur der jeweilige Ersteller. Diese Logik passt perfekt für klassische Anwendungsfälle wie Ticketsysteme, Aufgabenlisten oder formularbasierte Prozesse, bei denen Verantwortlichkeiten klar getrennt sind.
Solange alle Benutzer aktiv im System arbeiten, funktioniert dieses Setup auch reibungslos. Jeder kümmert sich um seine eigenen Daten, alles ist nachvollziehbar und sauber getrennt. Doch diese Stabilität hält nur so lange, wie sich an den beteiligten Personen nichts ändert. Und genau das ist in der Realität selten der Fall.
Der Klassiker tritt ein, sobald ein Mitarbeiter das Unternehmen verlässt. Über die Zeit hat dieser Benutzer eine Vielzahl an Einträgen erzeugt, sei es in Form von Aufgaben, Freigaben, Dokumentenzuordnungen oder anderen prozessrelevanten Daten. Diese Einträge bleiben natürlich bestehen, denn sie sind oft geschäftskritisch und müssen weiterhin gepflegt werden. Das Problem ist nur: Der ursprüngliche Besitzer existiert nicht mehr im aktiven Kontext.
Durch die gesetzte Berechtigung entsteht jetzt eine unsichtbare Blockade. Die Einträge gehören weiterhin dem alten Benutzer, und neue Verantwortliche können diese nicht bearbeiten. Das führt schnell zu ganz konkreten Auswirkungen im Arbeitsalltag. Prozesse bleiben stehen, weil niemand Änderungen durchführen kann. Daten veralten, weil sie nicht aktualisiert werden dürfen. Und Workflows laufen ins Leere, weil sie auf Informationen zugreifen, die nicht mehr gepflegt werden.
Genau dieses Szenario solltest du frühzeitig im Blick haben. Denn es ist kein Ausnahmefall, sondern eher die Regel in dynamischen Organisationen. Umso wichtiger ist es, eine Lösung zu haben, die dir diese Arbeit abnimmt und dafür sorgt, dass deine Daten und Prozesse weiterhin funktionieren.
Die saubere Lösung ist ein automatisierter Ansatz, bei dem die betroffenen Einträge von einem alten Benutzer auf einen neuen übertragen werden. Genau hier kommt ein Flow ins Spiel. Du übergibst einfach die alte und die neue E-Mail-Adresse, und der Flow übernimmt den Rest. Er findet alle relevanten Einträge und aktualisiert sie entsprechend.
Technischer Aufbau des Flows
Der Flow ist bewusst schlank gehalten, und genau das macht ihn so effektiv. Statt unnötiger Komplexität setzt du hier auf einen klaren Ablauf, der sich leicht verstehen und vor allem gut wiederverwenden lässt. Jeder Schritt greift sauber ineinander, sodass du am Ende einen stabilen Prozess hast, der genau das tut, was er soll.Der Einstieg erfolgt über einen manuellen Trigger. Das ist in diesem Fall kein Nachteil, sondern sogar gewollt. Du willst den Flow gezielt starten, wenn ein Benutzerwechsel stattfindet, und nicht permanent im Hintergrund laufen lassen. So behältst du die Kontrolle und kannst flexibel reagieren, ohne unnötige Ressourcen zu verbrauchen.
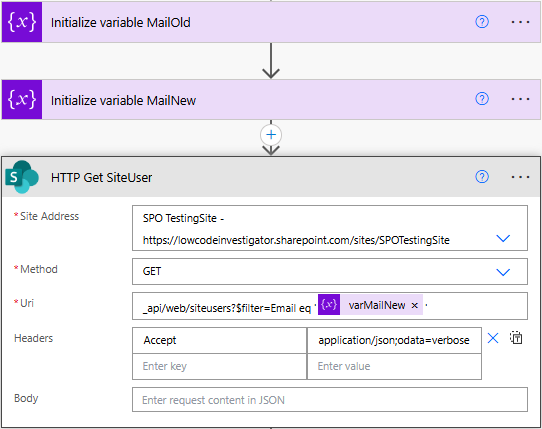
Loginname des Benutzers ermitteln
im ersten Schritt dient dieser HTTP-Call dazu, einen vorhandenen SharePoint-Benutzer anhand seiner E-Mail-Adresse eindeutig zu ermitteln, bevor der Listeneintrag aktualisiert wird. Dazu wird über die REST-API mit der Methode GET eine Abfrage an /_api/web/siteusers gesendet und per $filter auf die E-Mail aus der Variable MailNew eingeschränkt. Dadurch liefert der Aufruf gezielt den passenden Benutzer inklusive aller relevanten Eigenschaften. Entscheidend ist hier insbesondere der LoginName, da dieser später für das Setzen von Benutzerfeldern benötigt wird. Dieser Wert wird direkt aus der Antwort über den Ausdruck body('HTTP_Get_SiteUser')?['d/results']?[0]?['LoginName'] ausgelesen und im weiteren Verlauf verwendet. Somit stellst du sicher, dass die Aktualisierung des SharePoint-Eintrags sauber und mit der korrekten Benutzerreferenz erfolgt.
Power Automate |
_api/web/siteusers?$filter=Email eq '@{variables('varMailNew')}'Uri
Power Automate |
{
"Accept": "application/json;odata=verbose"
}Headers
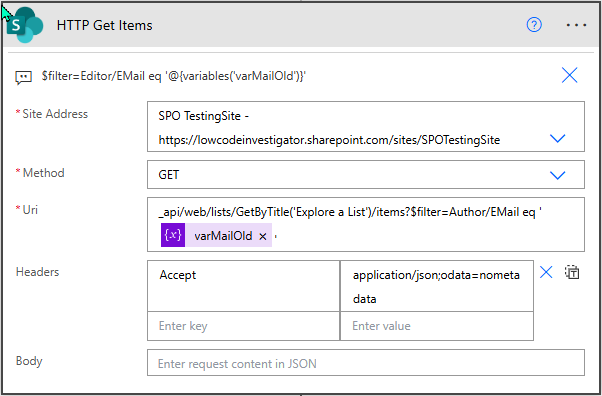
Listeneinträge abrufen
Im nächsten Schritt geht es darum, die richtigen Einträge zu finden. Und hier kommt der Filter ins Spiel, der oft unterschätzt wird. Statt einfach alle Listeneinträge zu laden, nutzt du eine gezielte OData-Abfrage:
Author/EMail eq 'varMailOld'
Editor/EMail eq 'varMailOld'
Damit stellst du sicher, dass wirklich nur die Einträge geladen werden, die vom alten Benutzer erstellt wurden. Das sorgt nicht nur für eine saubere Logik, sondern ist auch entscheidend für die Performance. Gerade bei großen Listen willst du vermeiden, unnötig viele Daten zu verarbeiten, weil das deinen Flow sonst spürbar ausbremst.
Power Automate |
_api/web/lists/GetByTitle('Explore a List')/items?$filter=Author/EMail eq '@{variables('varMailOld')}'Uri
Power Automate |
{
"Accept": "application/json;odata=nometadata"
}Headers
Die gefundenen Einträge werden anschließend in einer Schleife verarbeitet. Innerhalb von Apply to each wird jeder Datensatz einzeln durchlaufen und aktualisiert. Das gibt dir die Möglichkeit, sehr granular zu arbeiten. Du könntest hier zum Beispiel zusätzliche Bedingungen einbauen, bestimmte Einträge überspringen oder auch Logging ergänzen. Der Flow ist an dieser Stelle bewusst offen gehalten, damit du ihn an deine Anforderungen anpassen kannst.
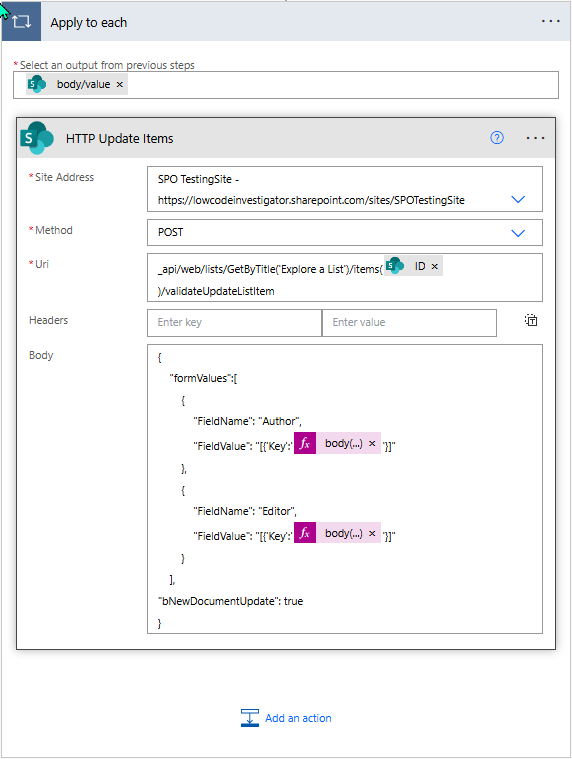
Einträge aktualisieren
Der wichtigste Teil kommt jetzt beim eigentlichen Update. Du willst das Feld Author ändern, also den ursprünglichen Ersteller eines Eintrags. Genau hier stößt du mit den Standardaktionen an Grenzen, weil es sich um ein Systemfeld handelt. Dieses lässt sich nicht ohne Weiteres überschreiben, zumindest nicht mit den üblichen Mitteln.Die Lösung ist ein direkter HTTP Request gegen die REST API. Der verwendete Endpoint sieht so aus:
_api/web/lists/GetByTitle('Explore a List')/items(ID)/validateUpdateListItem
Der entscheidende Punkt ist hier die Methode validateUpdateListItem. Sie ermöglicht dir, auch geschützte Felder wie Author oder Editor zu aktualisieren. Ohne diesen Ansatz würdest du an genau dieser Stelle nicht weiterkommen, weil die Standardaktionen schlicht nicht ausreichen.
Damit das Ganze funktioniert, musst du den neuen Benutzer im richtigen Format übergeben. Und genau hier liegt ein Detail, das häufig übersehen wird. Der Body des Requests sieht folgendermaßen aus:
Power Automate |
_api/web/lists/GetByTitle('Explore a List')/items(@{items('Apply_to_each')?['ID']})/validateUpdateListItemUri
Power Automate |
{
"formValues":[
{
"FieldName": "Author",
"FieldValue": "[{'Key':'@{body('HTTP_Get_SiteUser')?['d/results']?[0]?['LoginName']}'}]"
},
{
"FieldName": "Editor",
"FieldValue": "[{'Key':'@{body('HTTP_Get_SiteUser')?['d/results']?[0]?['LoginName']}'}]"
}
],
"bNewDocumentUpdate": true
}Body
Das Entscheidende ist das sogenannte Login:
i:0#.f|membership|user@domain.deWenn dieses Format nicht exakt passt, wird das Feld nicht aktualisiert. Oft bekommst du dabei nicht einmal eine klare Fehlermeldung, was die Fehlersuche unnötig schwierig macht. Genau deshalb solltest du diesen Punkt besonders im Blick behalten.
Warum ist dieser Ansatz jetzt so wertvoll? Ganz einfach: Du stellst sicher, dass deine Daten weiterhin bearbeitet werden können, auch wenn sich Benutzer ändern. Gleichzeitig verhinderst du, dass Prozesse ins Stocken geraten oder komplett ausfallen. Und weil der Flow generisch aufgebaut ist, kannst du ihn jederzeit wiederverwenden, ohne ihn neu bauen zu müssen.
Wenn du das Ganze produktiv einsetzt, kannst du den Flow problemlos erweitern. Du könntest zum Beispiel zusätzlich den Editor aktualisieren, automatische Trigger einbauen oder ein Logging ergänzen, um Änderungen nachvollziehbar zu machen. Auch ein sauberes Fehlerhandling ist sinnvoll, damit dein Flow stabil läuft, selbst wenn mal etwas nicht wie geplant funktioniert.
Am Ende hast du mit diesem Ansatz eine Lösung, die nicht nur ein konkretes Problem löst, sondern sich als wiederverwendbares Muster etabliert. Genau solche Patterns sind es, die dir im Alltag helfen, robuste und wartbare Lösungen aufzubauen.